鐵人賽第三十篇,想帶大家來探討聊天機器人(Chatbot)這塊的發展。
圖片來源:https://chatbotsmagazine.com/why-the-world-needs-chatbots-ae0c4abc33d5
拿今年夏天做的 Chatbot 簡報中的一張介紹市場上中文聊天機器人案例: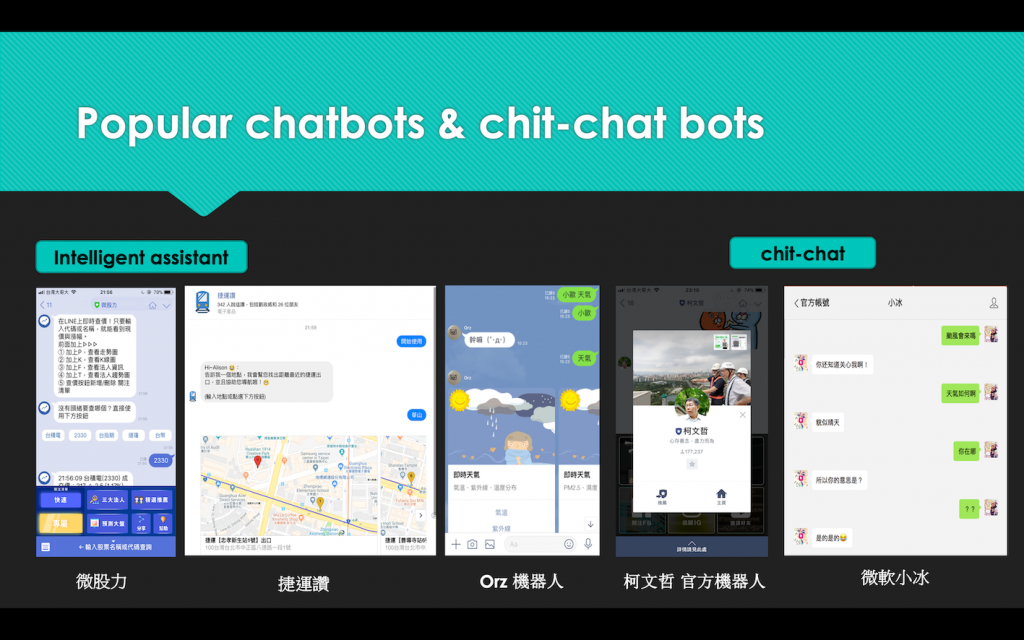
Chatbot 按照功能大略分成兩種:
再細分下去,可根據會話能力(Conversation capability)和回應機制(Response mechanism)來為 Chatbot 分類: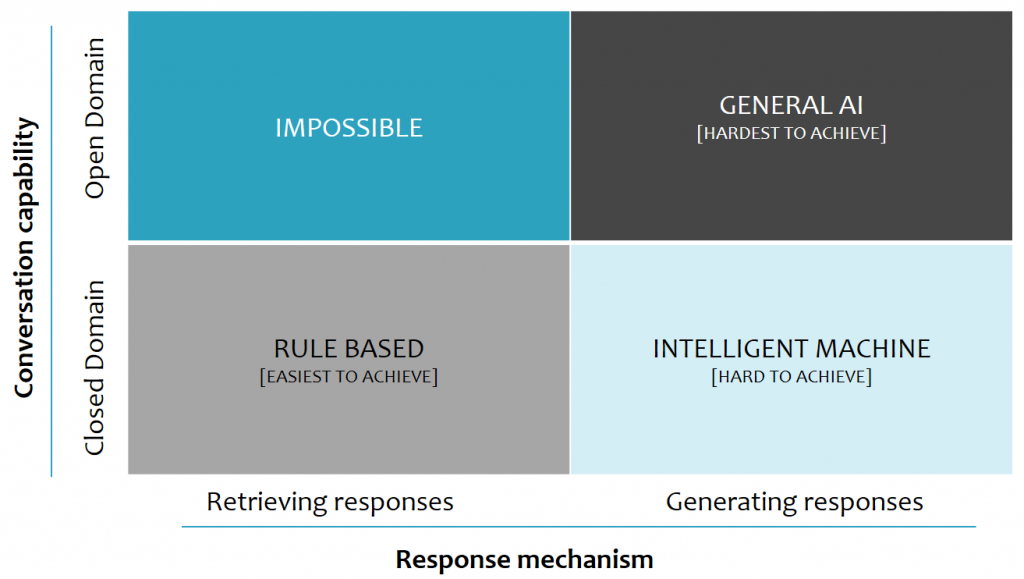
圖片來源:http://www.lempinenpartners.com/what-are-chatbots-and-how-they-impact-service-management/
智能助理和閒聊式機器人分別是Closed Domain 跟 Open Domain 的會話能力應用。在Open Domain的框架下,使用者不一定有明確的意圖,而 Chatbot 嘗試提供有意義的答案。這種無限制的對話加深了實現的困難度,實際測試過微軟小冰,小冰的反應比大部分聊天機器人來得有趣,不過硬要挑毛病的話,還是有存在對話不流暢的情況。反觀Closed Domain,系統引導對話轉向特定的主題並回答與預定義主題相關的問題,因此相對來說是比較容易的。
圖中 X 軸為回應機制:Retrieving responses 和 Generating responses,可以把模型分成這兩類。
input 和 context 選擇適當的 response。算法可以是規則模式(Rule based),也可以是用機器學習中的分類器來做。這種系统不會產生任何新的文本,它們只是從固定的集合中選擇一個 response。response 的場景response,通常基於機器翻譯技術。input 中的實體(Entity),讓人覺得聰明些Deep Learning 技術皆可用在基於檢索的模型(Retrieval-Based Models)或生成式模型(Generative Models)上。
深度學習技術論文
面臨的挑戰
Incorporating Context (融入情境)
Coherent Personality (連貫的人格)
例如對於語義相同的問題回覆一致的答案。
Evaluation of Models (模型的評估)
在論文《How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation》 中,研究者發現常用的評估指標中並沒有與人類的判斷有真正的關聯的,例如 BLEU 之類的指標(基於文本匹配)就不太適合。
Andrew Ng 曾說過目前 Chatbot 仍無法做到的是:進行真正有意義的對話。
Most of the value of deep learning today is in narrow domains where you can get a lot of data. Here’s one example of something it cannot do: have a meaningful conversation. There are demos, and if you cherry-pick the conversation, it looks like it’s having a meaningful conversation, but if you actually try it yourself, it quickly goes off the rails.
目前市場上的 Chatbot 系統大多是基於檢索式模型的應用,因為在產品系统內發生語法錯誤的代價是非常昂貴的,可能會導致用戶流失,這也是為什麼大多數系统採用基於檢索的方法,來避免掉語法錯誤和攻擊性的反應。
特別一提,生成式模型的開放領域(Open Domain)系統可說是通用人工智能(AGI,Artificial General Intelligence),目前離這個實現還很遠,但大量的研究在持續進行著。不過若是在限定領域(Closed Domain),生成式和檢索式的方法都是合適的。
大概在 Rule based 的對答系統下,加入生成式的因子,做 hybrid 的模型,會是一條比較可實行的路。
恭喜大大完賽! 
感覺還有後續...
耶~謝謝!
被你發現了...剩一篇結語而已~!
連看30天,要當個專業的揪粉啊
太感謝大大了~~~


